In the last post I talked about the non-RESTfulness of most "REST" api implementations. I will attempt to show a more RESTful implementation and some examples of how this benefits the software. While researching this topic, it became clear (by both lack of examples and poor examples) that this is a tough concept. Before I jump into the example, lets examine why its so hard - because these issues will drive some of the design.
Difficulties with API and REST
An Application Programming Interface (API) is supposed to be:
a set of functions, procedures, methods or classes used by computer programs to request services from the operating system, software libraries or any other service providers running on the computer.
And when creating a traditional API, you come up with methods and data formats to tell people how to "talk" to the system. But one of the primary REST tenets as mentioned by Roy Fielding is his blog is that you NOT have "out-of-band information driving interaction instead of hypertext." To put more simply, you should not pre-define the format of the data or the methods to be used, they should be discovered. But isn't that what an API is? How does one define the methods and the data formats but not have to know the methods or data formats? And why should I follow this "silly rule" anyway?
Well, the silly rule is the brilliance of REST and also what allows for the incredible flexibility that is the internet as we know today. If we know the format or the calls to make ahead of time, and write software against those, the control is no longer in the data providers hands. The control has shifted back from server to client. To understand the problem with this better, imagine that you wrote a custom browser and hard-coded it to a specific news article page with a fixed format and calling it silly that the news site wants to change the url or page format. (This example is stretched a bit far because an API has the understanding of being slightly more permanent than a generic webpage, but it still applies in spirit to RESTful APIs.)
The solution here is that there was a loophole of sorts, baked into the "Rules of REST" - note the last part in the rule: "out-of-band information driving information instead of hypertext." You can tell the client what it is allowed to do, as long as its part of the data (hypertext) being returned. The "media type" can have the information about what is allowed and what format things should be in! This, combined with the specifics of our chosen protocol (HTTP here), should give us all we need. So how do we do that?
REST Example
In the examples in the last post, the user logged in, searched for a product and created an order in both a traditional website and with a traditional API. So lets now make a REST version:
NOTE: I am going to ignore security at the beginning because it doesn't help in understanding the example, but I will discuss what could be done at the end.
Client starts with the root URL www.example.com/api/ and a discoverable media type apiIndex-v1+xml.
GET / www.example.com/api/ HTTP/1.1
Accept: application/vnd.example.coolapp.apiIndex-v1+xml
Response:
HTTP/1.1 200 OK
Content-Type: application/vnd.example.coolapp.apiIndex-v1+xml
<apiIndex>
<link>
<description>Customers</description>
<href>http://www.example.com/api/customers</href>
<type>application/vnd.example.coolapp.customers-v1+xml</type>
</link>
<link>
<description>Products</description>
<href>http://www.example.com/api/products</href>
<type>application/vnd.example.coolapp.products-v1+xml</type>
</link>
<link>
<description>Carts</description>
<href>http://www.example.com/api/carts</href>
<type>application/vnd.example.coolapp.carts-v1+xml</type>
</link>
<link>
<description>Orders</description>
<href>http://www.example.com/api/orders</href>
<type>application/vnd.example.coolapp.orders-v1+xml</type>
</link>
<link>
<description>Sessions</description>
<href>http://www.example.com/api/sessions</href>
<type>application/vnd.example.coolapp.sessions-v1+xml</type>
</link>
<link>
<description>API Help</description>
<href>http://www.example.com/api/help</href>
<type>text/html</type>
</link>
</apiIndex>
Here I have defined a set of valid hyperlinks the client can travel to from the root. It is reasonable to assume that the client could get more stuff or less stuff depending on what the business wanted to provide at the root, or based on what the user is authorized to use. This exchange would be the equivalent of a generic "index.html" page for the web. The client could show the descriptions as buttons or a drop down or whatever makes sense for the client (but it doesn't matter at the API level because it is not providing a page to be rendered, just resources to be processed as the client sees fit).
Lets say the client chooses to view a list of products, but does not know the allowed operations - the client could then perform an HTTP OPTIONS call against the resource to get the list (there are few standards for the format of the response of an OPTIONS call, but I went with a custom response body for the API to show a useful example):
OPTIONS /api/products
Response:
HTTP/1.1 200 OK
ALLOW: HEAD,GET,OPTIONS
Content-Type:application/vnd.example.coolapp.options-v1+xml
Content-Length: 1032
<options>
<methods>
<method>
<type>GET</type>
<description>Retrieve a list of products</description>
<parameters>
<parameter>
<name>Keyword</name>
<type>string</type>
<required>false</required>
</parameter>
<parameter>
<name>MaxResults</name>
<type>integer</type>
<required>false</required>
</parameter>
<parameter>
<name>StartIndex</name>
<type>integer</type>
<required>false</required>
</parameter>
</method>
</methods>
...
</options>
Now seeing the options and the calling parameters, the client then provides a product search entry form in its UI, and then decides to perform the search against the API:
GET /api/products?Keyword=green%20widget
Response:
HTTP/1.1 200 OK
Content-Type:application/vnd.example.coolapp.product-v1+xml
Content-Length: 1032
<products>
<resultInformation>
<totalItems>3923</totalItems>
<maxResults>15</maxResults>
<maxBytes>10000</maxBytes>
<startIndex>1</startIndex>
<endIndex>15</endIndex>
</resultInformation>
<product>
<id>12343</id>
<description>389349 green widget with bells</description>
<price currencyCode="USD">3.56</price>
<link>
<description>Product 12343</description>
<href>http://www.example.com/api/products/12343</href>
<type>application/vnd.example.coolapp.product-v1+xml</type>
</link>
</product>
<product>
<id>2343</id>
<description>2343 green widget copper clad</description>
<price currencyCode="USD">4.93</price>
<link>
<description>Product 2343</description>
<href>http://www.example.com/api/products/2343</href>
<type>application/vnd.example.coolapp.product-v1+xml</type>
</link>
</product>
...
</products>
The client then processes the results and allows the user to add items to a cart. This can be done against a cart resource so that the cart object is validated by the server (minimum quantities, availability, etc) and so that the client can save the cart if it doesn't want to commit to an order just yet:
POST /api/carts
Content-Type:application/vnd.example.coolapp.cart-v1+xml
Content-Length: 1032
<cart>
<customerId>1343</customerId>
<lineItems>
<lineItem>
<productId>12343</productId>
<quantity>4</quantity>
</lineItem>
<lineItem>
<productId>39293</productId>
<quantity>2</quantity>
</lineItem>
...
</lineItems>
</cart>
Response:
HTTP/1.1 201 Created
Location: /api/carts/323392
Now that the cart is all set, perhaps the client decides to create an order:
POST /api/orders
Content-Type: application/vnd.example.coolapp.order-v1+xml
Content-Length: 2939
<order>
<customerId>1343</customerId>
<lineItems>
<lineItem>
<productId>12343</productId>
<quantity>4</quantity>
</lineItem>
<lineItem>
<productId>39293</productId>
<quantity>2</quantity>
</lineItem>
...
</lineItems>
</order>
Response:
HTTP/1.1 201 Created
Location: /api/orders/O293920
That is the basic REST API example.
Security Aside
Let me walk through some of the security handling in this example since it can be confusing the first time you work through it. When you hit the index page for the API, the server would likely be expecting a valid session token in the form of an "Authorization" header so that we can authorize access to resources appropriately. If that header is not present, the server could send back a 302 redirect to a session resource (so that the client could submit a username and password to get a valid session) like so:
GET /api HTTP/1.1
Accept: application/vnd.example.coolapp.apiIndex-v1+xml
Response:
HTTP/1.1 302 Moved
Location: http://www.example.com/api/session
At which point the client could do an OPTIONS to learn the valid session options (not shown), then POST credentials to get a new session resource back:
POST /api/session
Content-Type: application/vnd.example.coolapp.sessionCredentials-v1+xml
Content-Length: 100
<sessionCredentials>
<username>joe</username>
<password>opensesame</password>
</sessionCredentials>
Response:
HTTP/1.1 201 Created
Location: http://www.example.com/api.session/74823
Content-Type: application/vnd.example.coolapp.session-v1+xml
Content-Length: 203
<session>
<id>74823</id>
<token>293929FDAAECD3293FFA32</token>
<username>joe</username>
</session>
Typically, you could do something similar to all resources, but probably using 401 Not Authorized instead of the redirect since you really want the user to go through the index page instead of "knowing" the URL ahead of time. This is just a quick example of security and there are a lot of security vulnerabilities here that you should be careful to avoid. Plus, the client would have to start over at the index page, using the valid token - which is a little awkward. There are dozens of different ways to handle security, like OAuth, BASIC Authentication, etc, so more research is warranted with this topic, but you get the basic idea.
So now let me talk about some of the nuances with the flow.
Notes about REST APIs
I am going to parallel these comments with my interpretation of the "rules" that Mr. Fielding presented in his REST blog post.
- The only thing the client should know ahead of time is the root URL. It shouldn't know or expect as specific resource to be available. For example, the client can't assume an "order" resource or a "search" resource - those should be provided as choices to the client from the server.
The first thing to note is that although the client only knows the root URL, it still must be coded to handle the link structure that was defined for the root, plus the media types that were presented. It is very difficult to avoid writing something akin to a browser when consuming a REST API. To create a client properly in this example, it should handle the creation or deletion of links on the index page, and gracefully handle any unknown media types that are presented. Otherwise, you are just basically making an RPC call, because you both know the format and nothing can change without both sides changing. That destroys the REST concept and prevents changes from occurring as seamlessly as it should (such as the host deciding to change the URL, or alter the flow through the API.)
- "A REST API should spend almost all of its descriptive effort in defining the media type(s) used for representing resources and driving application state, or in defining extended relation names and/or hypertext-enabled mark-up for existing standard media types."
The bulk of what can be done or what is available is meant to be part of the object that is returned. You will notice above that I included a special "resultInformation" block in the product search results. This allows the client to present a "1 of X" link in the app, or make multiple requests to cycle over the results from the server (and limit the bandwidth from the server). Also you will notice that the flow through the API does not jump around, for example, already "knowing" the URL of orders. You don't just jump to /api/orders/123, because the server may have moved it, or deleted it, or you may not be authorized to view it. If you want to give the client the ability to view orders, you create an orderView resource that returns a displayable form of the order and lets the client pick from a list. (server is in control what is available).
- "A REST API should not contain any changes to the communication protocols aside from filling-out or fixing the details of under specified bits of standard protocols, such as HTTP’s PATCH method or Link header field."
You will notice above that I presented a use of the HTTP OPTIONS method to assist with the consumption of the API, but tried to stay within the bounds of what is "standard" HTTP. In a normal non-REST API, these method signatures are predefined in a document and both sides code to them. If you do that in REST, you couple the client and server so that neither may change without the other changing. You want the server to decide what is presented and make the client smart enough to handle those choices. Again, it is very difficult to write a client that that is not browser-like and is a little unnatural for an API, but gives great power to the server to evolve.
Again, I have been more long-winded with my post that I would like, but hopefully it gives some value to the developers and REST-ees out there. This was a very difficult post for me to come up with because I had to constantly focus on the REST principles and avoid the classic API mindset. I found it very helpful to discuss with colleagues and to compare what a browser does with what we are trying to get out of the API. There are lots of things that I didn't have space to discuss, like versioning, content-negotiation, internationalization, etc that make this a very rich communication platform to build on. I would appreciate any comments or questions about this flow and REST in general. I know that there are things I can do better, and things that likely need fixing (and that everyone is going to do it differently for their purposes since there is no "right way") so be sure and add a comment.
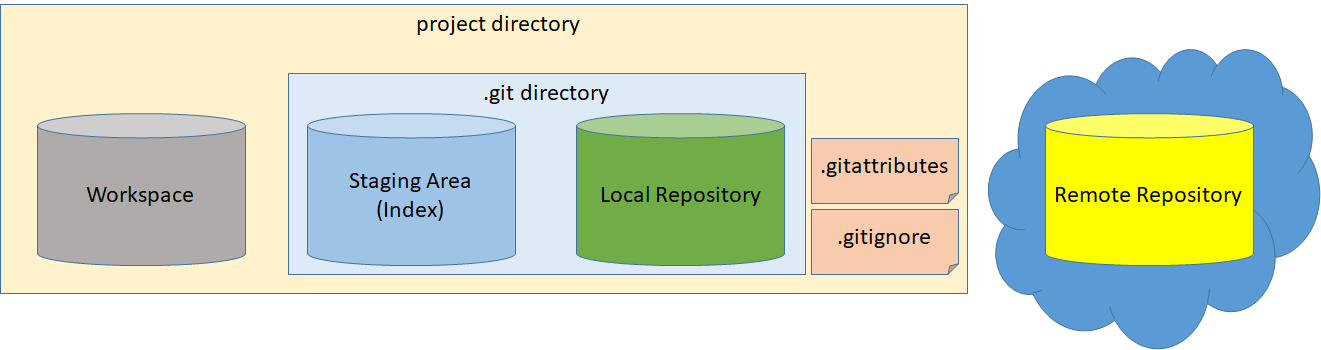
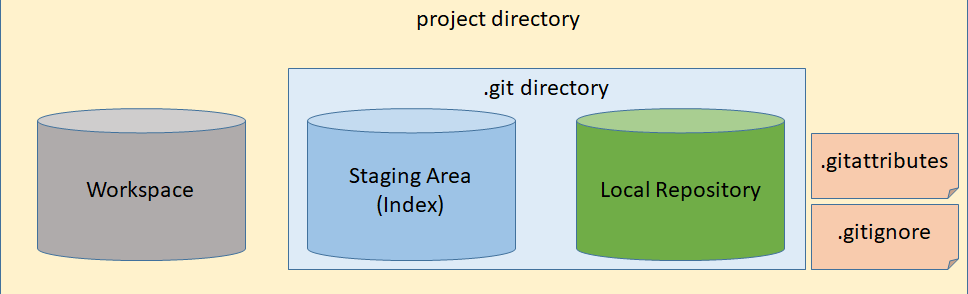
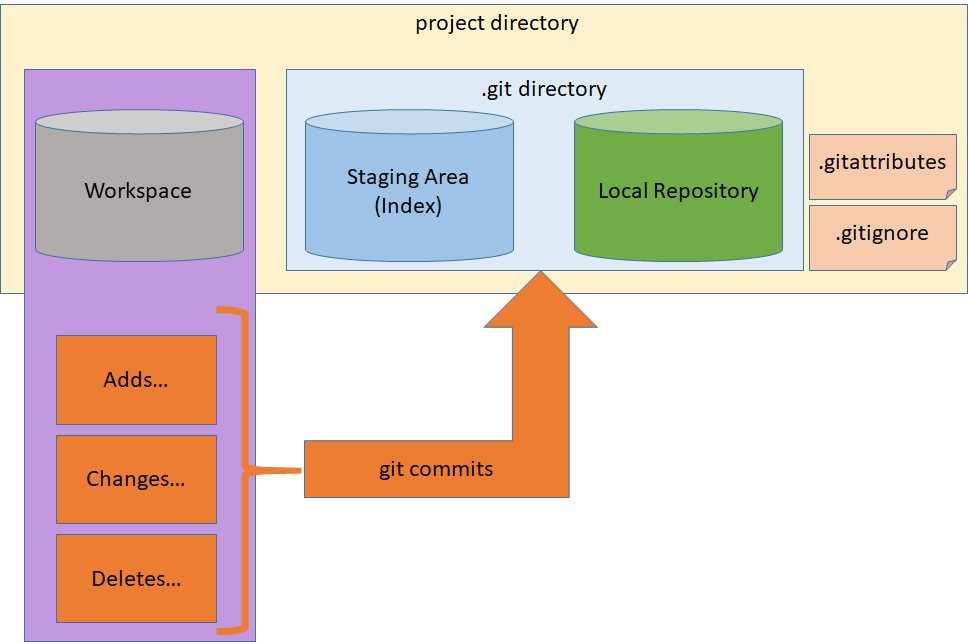

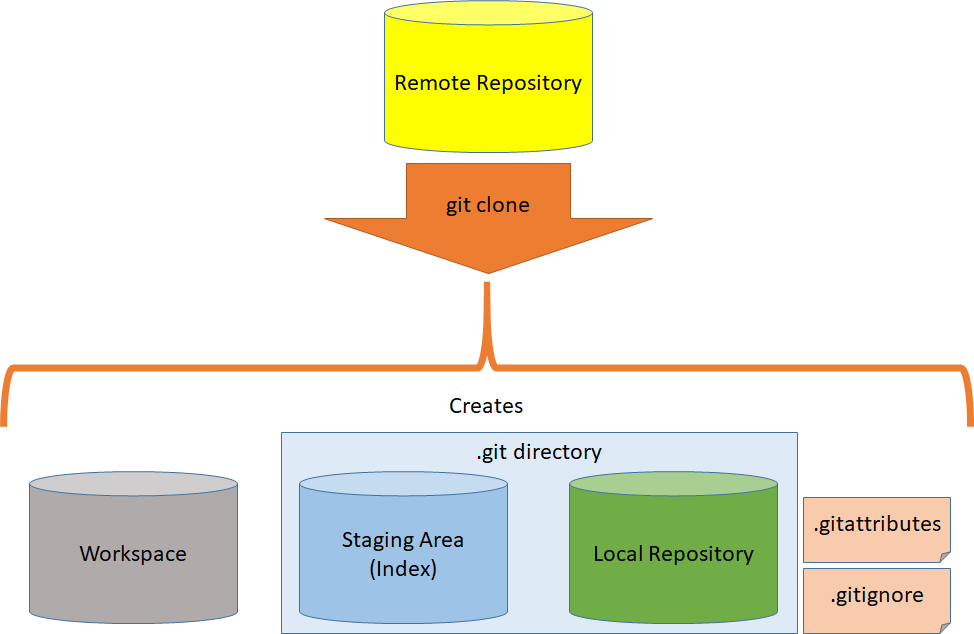
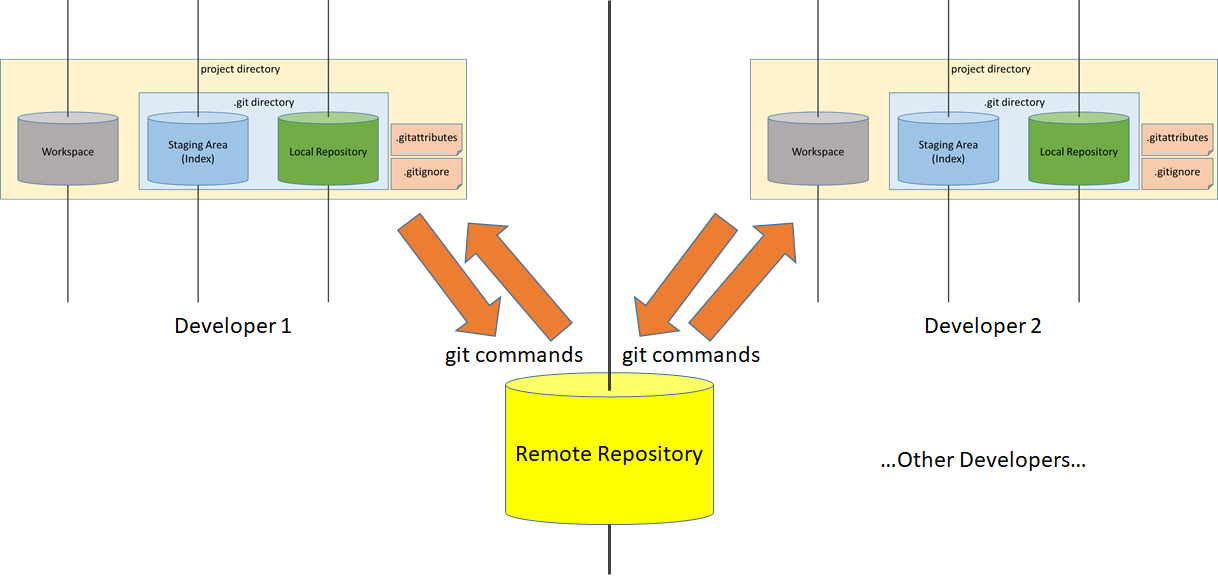
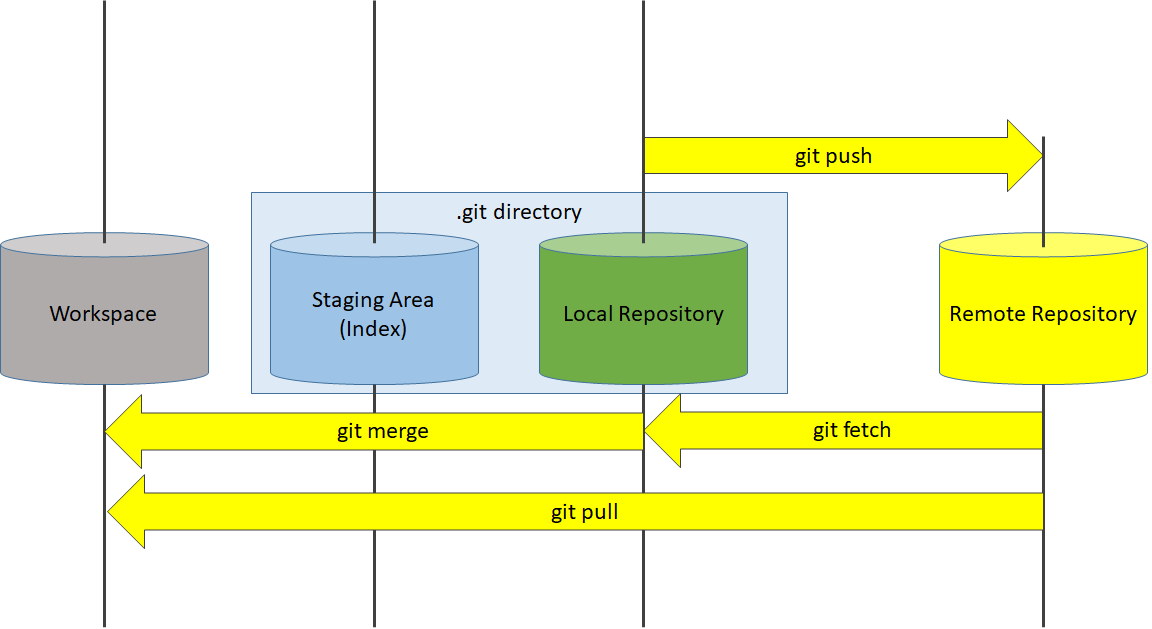
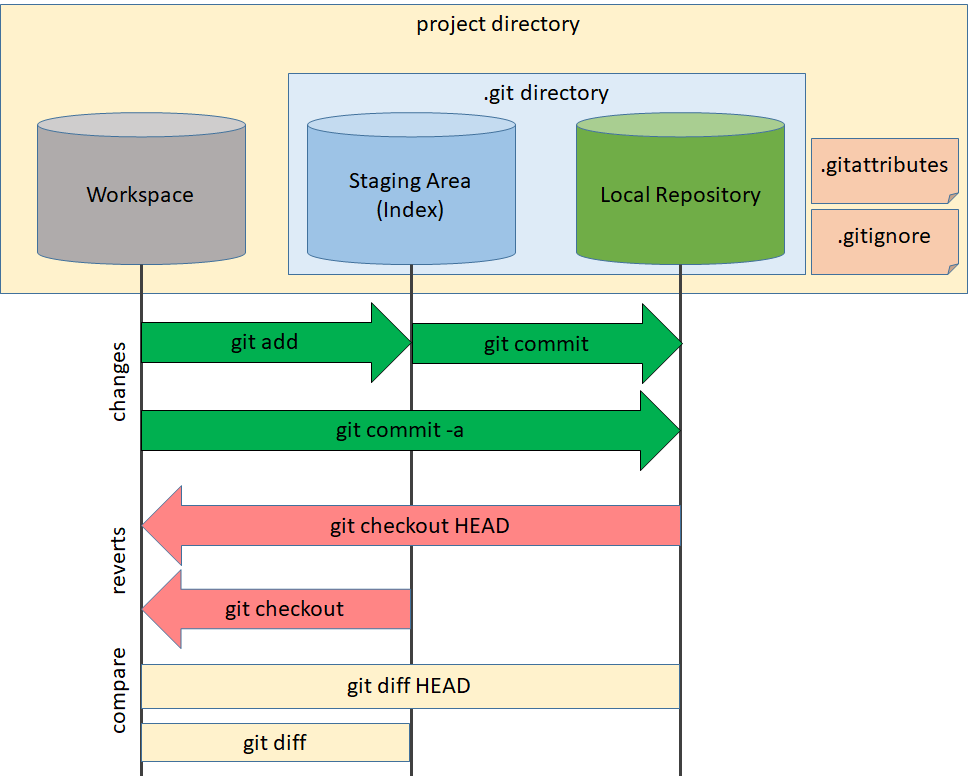

 Master branch developers would be performing these commands while making changes:
Master branch developers would be performing these commands while making changes: